

Introduction to Google DeepMind and V2A

Renowned for its revolutionary work in machine learning and artificial intelligence (AI), Google DeepMind is a globally recognized research center in AI. One of its noteworthy innovations that aims to push the limits of AI is V2A. It integrates a number of machine learning techniques to improve comprehension, problem-solving, and decision-making abilities.
What is V2A?

“Vision to Action,” or V2A for short, is a concept intended to close the gap between visual perception and action. It focuses on assisting robots or artificial intelligence (AI) systems in turning what they perceive (via visual data) into actions that have meaning and purpose. Robots, self-driving cars, and other AI systems that must communicate with the outside world require an understanding of this idea.
How V2A Works
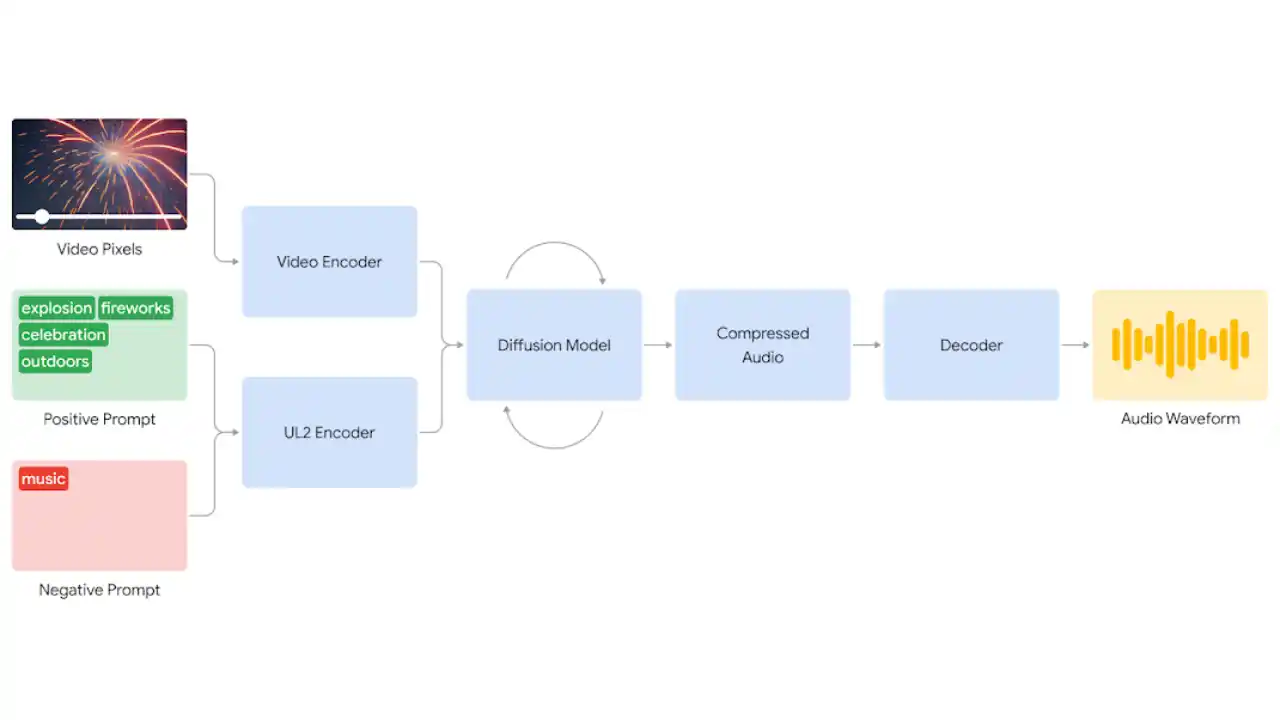
V2A is fundamentally constructed with deep learning techniques. Convolutional neural networks (CNNs) are used to interpret visual input (such as images or movies), and transformers or recurrent neural networks (RNNs) are used to model decision-making and action stages. Large datasets are used to train these AI models, which imitate how people see, interpret, and respond to visual signals.
Key Features of V2A
Vision Processing:

V2A has the ability to take unprocessed visual data and turn it into useful information.
Action Prediction:

With feedback from the visuals, it can anticipate the right response.
End-to-End Learning:
Without requiring manually written rules, V2A integrates learning from data directly, enabling it to generalize across many jobs.
Adaptability:
Its versatility for real-world applications stems from its ability to adapt to various events and environments.
Applications of V2A
Autonomous Vehicles:

In order to navigate safely, self-driving cars need V2A to help them comprehend their surroundings and make fast, precise decisions.
Robotics:

V2A-capable robots are able to see objects, comprehend their environment, and respond appropriately by picking things up or navigating tricky areas.
Healthcare:

Through the analysis of medical images and the recommendation of treatments based on visual assessments, AI systems utilizing V2A can help physicians.
Training V2A Models

DeepMind leverages enormous datasets with pictures, movies, and action sequences to train V2A. The model learns by analyzing the relationships between what it sees and the actions humans or machines take in response. It improves with time at predicting the optimal course of action based on fresh, unseen visual inputs.
Challenges in Developing V2A

There are obstacles in the way of building V2A. Making sure the AI model is able to generalize across various circumstances and environments is a significant challenge. A model that has been trained to identify items in one environment, for instance, might not perform well in another. Making sure the AI can act quickly and in real time is another problem, particularly for important applications like autonomous driving.
Advancements in V2A Technology

The performance of V2A has greatly improved with recent developments in neural network topologies, such as transformers and self-supervised learning. With the use of these technologies, the model can process intricate data sequences, improve its capacity for generalization, and make judgments more quickly. The development of V2A has also been aided by advancements in computing power and cloud-based infrastructure.
Comparison with Other AI Systems

V2A is unusual in that it integrates perception and decision-making, whereas most AI models concentrate on one or the other separately. While traditional AI systems may be quite good at recognizing images, they are not very good at acting on that knowledge. This restriction is addressed by V2A, which smoothly integrates action output and visual input.
The Future of V2A

In the direction of developing more sophisticated and self-sufficient AI systems that can function in the actual world, V2A is an important step forward. V2A may eventually result in more intelligent robots, enhanced AI assistants, and better autonomous cars. Models like V2A will probably get even more advanced as AI research progresses, enabling AI systems to view and interact with the world more skillfully.
In summary
Google DeepMind has developed a cutting-edge technique called V2A that attempts to close the gap between AI systems’ perception and action. It has several uses in fields including autonomous driving, robotics, and healthcare because of its capacity to understand visual data and anticipate actions. Notwithstanding difficulties, V2A’s creation represents a significant advancement in AI research and real-world applications.
Share this content:












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
+ There are no comments
Add yours